Migrating and evolving services in production
In this post, I want to tell you about a recent project that I have been working on at my current employer, lastminute.com. We wanted to introduce a new system to replace an existing one, and we needed to do that without any downtime or losing any data. Let us discuss what we did and how!
Background
Our team is working on rebuilding the process that is executed whenever a flight in your reservation is delayed, changed, or canceled. In such cases, we are notified by the airlines of the changes in their schedules, and we take care to inform our customers and support them in adapting their travel plans accordingly. Through the section of our site called My Area, customers can see the list of their own reservations, select alternative flights, or get a refund.
Our company has a lot of reservations - millions every year! - and flight reschedules and cancellations are a pretty common occurrence: our process is exercised thousands of times per day! While we have a lot of automation in place, we still had a certain percentage of corner cases that weren’t covered and required being handled manually by our customer support agents. We also wanted better tracking and analytics on the overall process, to help us understand how to reduce friction for the customer. Finally, we really wanted to improve the code quality of the existing system and its observability.
For all these reasons - and since the actual codebase size was small enough, we decided to do a full rewrite, even though you should never do that according to some people 😊. Obviously, we didn’t want to do a long rewrite with a big-bang release - after all, agile is a thing we practice and believe in at lastminute.com! We release often, with small increments, and we adjust our direction constantly. Thus, we wanted to build a new service that would handle this process, migrate the old systems one step at a time, all without losing data or having any downtime. How did we do that?
Hot migration of databases
The approach we have used to replace it has been something along these lines:
- replace one part of the overall process at a time, keeping the old system alive, but implementing the functionality in the new system;
- letting writes go through both systems;
- implementing a “back filling” job to sync all the existing data in the new system;
- replacing the reads from the old system with reads from the new one;
- removing the old system altogether.
This is pretty much the standard way to do things like these, and it is often known as the Strangler Fig. We didn’t do anything particularly innovative, however, we had a pretty good execution: we experience no downtime at all, nor did we lose or mangle any data.
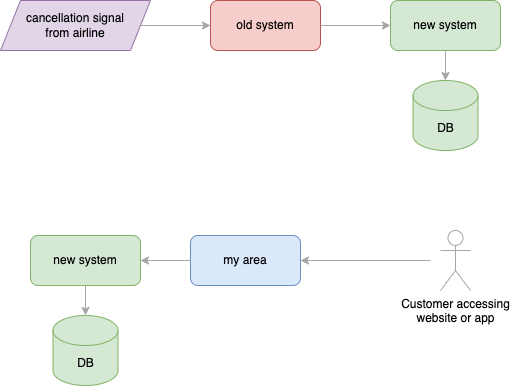
Let us dig into a particular case: showing that a flight was canceled in the customer’s My Area. Previously, the information was stored in the My Area service’s database:
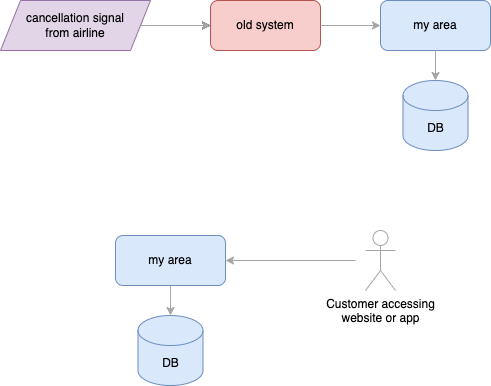
The first step that we released was to plug the new system “in the middle” of the flow, leaving parts of the business logic in the legacy one and still communicating with the existing My Area system. However, we also started saving data in the new system’s database:
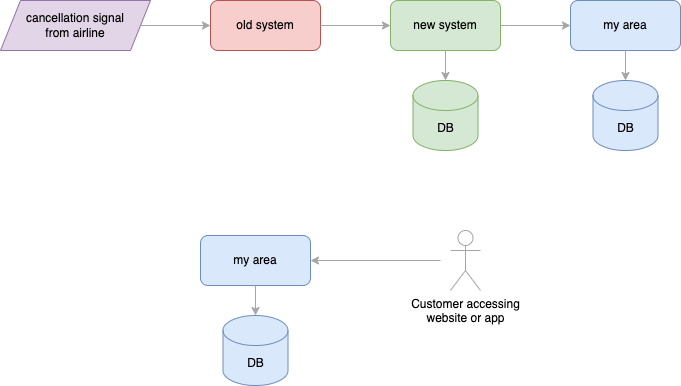
In this way, we started populating the database for all signals that we received from the release onward.
The next step was filling the database with all the existing data: to do so, we created a job that copied data from the old db to the new one:
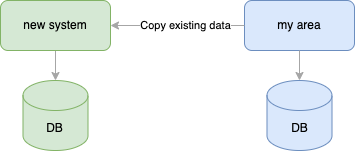
After this was done (and we validated the migrated data), we started using the new system as the source of truth for the data:
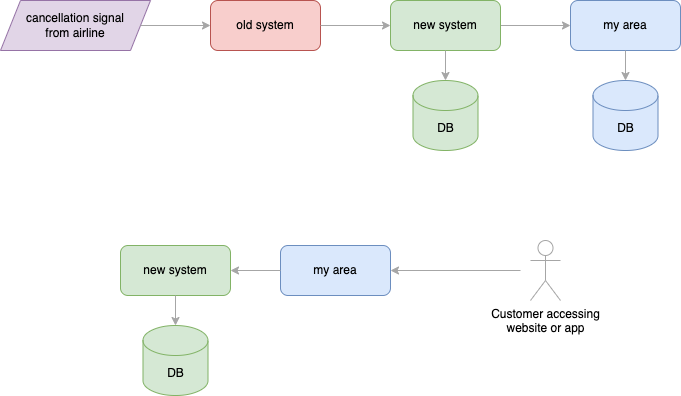
Finally, we had a last “clean-up” release, where we removed the old database from the My Area system:
Shadow calls
Something that helped us a lot during this process has been implementing “shadow calls”: after first implementing a functionality in the new system, we introduced in the old system a temporary call to the new one. Then, in the old system, we added a comparison between the old business logic and the result of the new system, and we used metrics and logs to understand whether we were doing the correct job or not. We introduced alerts that notified us on Slack when we had discrepancies and had logs to help us understand the reasons for them.
After we felt that the new system was implemented correctly, we removed the old business logic and we started using only the output of the new system. This has helped us find some bugs and edge cases that we had not understood correctly, and gave us a lot of confidence in the new system.
The code was something like that:
fun shadowCall(inputs) {
val oldProcessResult = processSignalUsingOldProcess(inputs)
val newProcessResult = doHttpCallToNewSystem(inputs)
if (oldProcessResult != newProcessResult) {
recordMetric("mismatch")
logError(
"We had a mismatch for inputs {} - old process returned {} and new system {}",
inputs, oldProcessResult, newProcessResult
)
}
return oldProcessResult
}
Lessons learned
We are a large website, with millions of customers, and any downtime during migrations has an impact in terms of lost revenues and customer satisfaction. We also practice continuous delivery and release in productions dozens if not hundreds of times per day.
Therefore, any migration must be done in small steps, to ensure that the whole system is always usable and never loses data. In turn, this implies that there may be many “small” releases of temporary code, that will get removed a few days later, but that is ok - and pretty normal when practicing CD. Small releases are a lot safer than big ones, and having a fast feedback loop is fundamental - this is the core tenet of Agile, after all.
We believe that the most important things we have done were:
- write automated tests - we used a lot of unit tests, a reasonable number of carefully designed integration tests, and contract tests;
- validating the new implementation with shadow calls (where it made sense);
- put a lot of effort into ensuring that our system was observable, and that any problem would be visible in our Grafana dashboards and alert us immediately on Slack.
This post by Shopify has a great write-up of a very similar experience, if you wanna see another take on the topic.