Introduction to Parsing - 11
This post is part of the Introduction to parsing series.
In the last part we completed our preliminary work. This time, we’re finally modify our parser to use the new tree structure we’ve built.
The commit we will discuss in this post is here. The commit includes a lot of changes all at once, so we are going to go through it rather slowly.
First step: adapting variables Link to heading
We have to modify the various methods in the parser that used to handle expressions, terms, factors and similar so that they now return a NodePtr, rather than evaluating immediately the source and return a double as they did before.
To see what we mean, let’s see how we are going to change evalNextVariable: we’re going to rewrite it from this:
double Parser::evalNextVariable() {
// Match the variable name
std::string variableName = getNextToken().getContent();
advance();
// Lookup its value
auto it = variables_.find(variableName);
if (it == variables_.end()) {
throw UnknownVariableName(variableName);
}
return it->second;
}
to this:
NodePtr Parser::evalNextVariable() {
// Match the variable name
std::string variableName = getNextToken().getContent();
advance();
// Make a variable access node
return NodePtr(new VariableNode(variableName));
}
We aren’t changing the parsing code; only what we do with what we have parsed. Instead of immediately getting the variable’s value and returning, we’re returning a new VariableNode that will access the variable’s value when eval will be called.
Next: factors Link to heading
Similarly to before, we’re going to change evalNextFunctionCall from:
double Parser::evalNextFunctionCall() {
// Match the function name and the open parenthesis
std::string functionName = getNextToken().getContent();
advance();
match(TokenType::OPERATOR, "(", "an open parenthesis");
// Is it a valid function?
doubleToDoubleFunction f = lookupFunctionByName(functionName);
// Eval its argument and match the closed parenthesis
double argumentValue = evalNextExpression();
match(TokenType::OPERATOR, ")", "a closed parenthesis");
// Call the function!
return f(argumentValue);
}
to:
NodePtr Parser::evalNextFunctionCall() {
// Match the function name and the open parenthesis
std::string functionName = getNextToken().getContent();
advance();
match(TokenType::OPERATOR, "(", "an open parenthesis");
// Parse its argument as a node and match the closed parenthesis
NodePtr argument = getNextExpressionNode();
match(TokenType::OPERATOR, ")", "a closed parenthesis");
// Make a function call node
return NodePtr(new FunctionCallNode(functionName, argument));
}
Notice how in the previous version we used to evaluate immediately the arguments of the function by calling evalNextExpression, while now we are calling the new method getNextExpressionNode to parse an expression as a NodePtr. The evaluation of the function’s argument is now delayed until the function call node is actually evaluated.
Let’s continue and see how evalNextParenthesisFactor changes. This is the old version:
double Parser::evalNextParenthesisFactor()
{
// Match the '('; parse an expression; then match the ')'
match(TokenType::OPERATOR, "(", "an open parenthesis");
double value = evalNextExpression();
match(TokenType::OPERATOR, ")", "a closed parenthesis");
return value;
}
and this is the new one:
NodePtr Parser::evalNextParenthesisFactor()
{
// Match the '('; parse an expression; then match the ')'
match(TokenType::OPERATOR, "(", "an open parenthesis");
NodePtr node = getNextExpressionNode();
match(TokenType::OPERATOR, ")", "a closed parenthesis");
return node;
}
Given that parenthesis are implied by the tree structure, there’s no special need of a Node subclass for them.
Finally, we have to change the first lines of evalNextFactor to handle numbers, from:
double Parser::evalNextFactor()
{
if (getNextToken().getTokenType() == TokenType::NUMBER) {
double value = atof(getNextToken().getContent().c_str());
advance();
return value;
to:
NodePtr Parser::evalNextFactor()
{
if (getNextToken().getTokenType() == TokenType::NUMBER) {
double value = atof(getNextToken().getContent().c_str());
advance();
return NodePtr(new NumberNode(value));
Terms and expressions Link to heading
The changes to terms and expressions parsing are very similar to each other, so we will show only the terms here . The code was changed from:
double Parser::evalNextTerm()
{
// First handle numbers and parenthesis
double value = evalNextFactor();
// Next handle multiplications and divisions
while (hasNextToken() && getNextToken().getTokenType() == TokenType::OPERATOR) {
if (getNextToken().getContent() == "*") {
advance();
value *= evalNextFactor();
} else if (getNextToken().getContent() == "/") {
advance();
value /= evalNextFactor();
} else {
// An operator, but not '*' or '/': let the caller handle it.
break;
}
}
return value;
}
to:
NodePtr Parser::evalNextTerm()
{
// First handle numbers and parenthesis
NodePtr node = evalNextFactor();
// Next handle multiplications and divisions
while (hasNextToken() && getNextToken().getTokenType() == TokenType::OPERATOR) {
if (getNextToken().getContent() == "*") {
advance();
node = NodePtr(new MultiplicationNode(node, evalNextFactor()));
} else if (getNextToken().getContent() == "/") {
advance();
node = NodePtr(new DivisionNode(node, evalNextFactor()));
} else {
// An operator, but not '*' or '/': let the caller handle it.
break;
}
}
return node;
}
Basically, instead of immediately evaluating the multiplications and divisions, we build a new node whose left child is what we have parsed so far, and the right child is the next factor.
Let’s say we are parsing 1 * 2 / 3. At the first iteration first we’re going to build a NumberNode for 1. Next, we are going to replace node with a MultiplicationNode, whose left child is the NumberNode(1) and the right child is the next factor, so a NumberNode(2). Finally, at the last iteration, node will refer to a new DivisionNode, whose left child will be the old MultiplicationNode and the right child will be a new NumberNode(3):
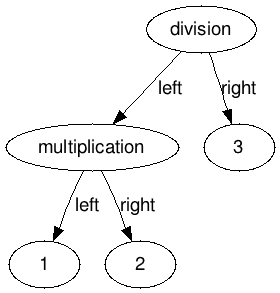
Last changes Link to heading
We have seen how we have changed most methods to return a NodePtr rather than evaluate the expression immediately. However, we also need to actually evaluate the nodes we build. This is done with a new method:
double Parser::evalNode(NodePtr node)
{
EvaluationContext evaluationContext(functions_, variables_);
return node->eval(evaluationContext);
}
With this helper method, parseExpression changes from:
void Parser::parseExpression()
{
double value = evalNextExpression();
ostream_ << value << std::endl;
}
to:
void Parser::parseExpression()
{
NodePtr node = getNextExpressionNode();
ostream_ << evalNode(node) << std::endl;
}
A similar change has to be done in parseAssignment, since we only need to store variables’s values and not the expression used to evaluate them:
// The new parseAssignment
void Parser::parseAssignment()
{
// Match variable name
if (!hasNextToken() || getNextToken().getTokenType() != TokenType::IDENTIFIER){
throw InvalidInputException("Found an unexpected token: " + getNextToken().getContent());
}
std::string variableName = getNextToken().getContent();
advance();
// Match =
match(TokenType::OPERATOR, "=", "the assigment operator =");
// Get the expression as a node, evaluate it and save the variable value
NodePtr node = getNextExpressionNode();
variables_[variableName] = evalNode(node);
};
After these changes, with just a trivial change to the unit tests (they now have to call evalNode and getNextExpressionNode rather than the old evalNextExpression we see that our parser works as expected!
Conclusions Link to heading
The groundwork is complete and our parser has been rewritten to use our nodes. In the next two parts, we’re going to finally let the user define new functions.