Future Java releases - part three
This post is part of the Future Java Releases series · Part 3 of 3
View series →- 01
- 02
-
03
Future Java releases - part three Current post
In this third and last post in the future of Java series, we will focus on another great new feature of the JVM, designed to improve performance. But, before talking about the language and JVM evolution, I am going to give you some background on what this enhancement plans to improve.
Value classes and primitive wrappers Link to heading
It is pretty common, in Java and in OOP languages in general, to talk about value classes. These are objects which are immutable and are designed to not have a reference identity, meaning that any instance of that class with the same state (i.e. fields’ values) would have the same behavior and should be indistinguishable from any other.
Classical examples from the JDK are the primitive wrapper classes (Int, Long, and so on); BigDecimal; Optional; or the date classes from Java 8 (LocalDate, OffsetDateTime, etc). Often you do not even create instances of these classes directly via their constructor, but you use some static factory methods. Furthermore, you might want to create your own tiny value classes, to avoid the primitive obsession smell, as I have discussed in a recent blog post.
Let us focus a bit on the primitive wrapper classes.
Primitive wrappers and performances overhead Link to heading
As you probably know, the seven primitive types in Java are very different from any other type (which extends Object). They have their own bytecode instructions, and we need the wrapper classes, via boxing/unboxing, to use them with reflection or generics - with all the performance hits that this causes. We even got horrible things like IntStream in Java 8, just to have some methods like sum!
Let us focus a bit on the performance hits that the wrapper classes cause, in particular when used with generics. Imagine you have an ArrayList<Integer> with three values. In memory, you have a lot of objects:
- the
ArrayListitself, - the backing
Integer[]array, - the three
Integerobjects, in three separate and random memory locations, containing the threeint.
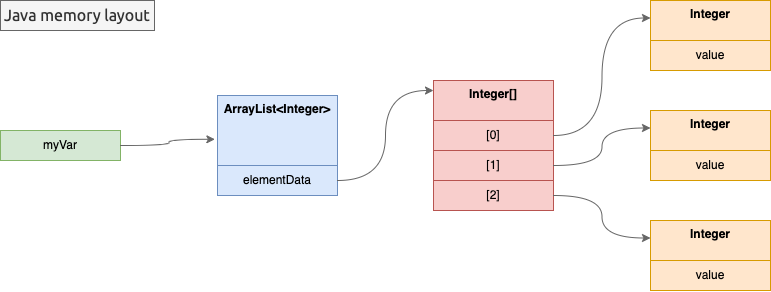
This not only wastes quite a bit of memory, but also requires a lot of roundtrips between CPU and memory to access the underlying int - and, as you should know, accessing the memory is pretty slow! Furthermore, this is not CPU cache-friendly, since we need to fetch a lot of data. If you are unfamiliar with how the CPU cache lines work, as a very brief introduction, you should know that your CPU fetches always multiple bytes at a time (generally 32, 64, or 128) - never just one bit or byte. Thus, with all the accesses you need to get to one of the underlying int, you will fetch a lot of extra bytes that will occupy the CPU L1/L2 caches.
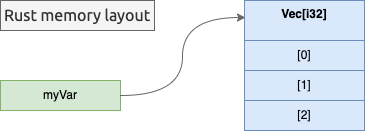
Compare this with C++, Rust, or Go: in all these languages, you would have a pointer (or some equivalent concept that would map to the address of the first byte of the array), and you would have the three integers stored in 12 bytes of contiguous memory, that will be fetched in one memory access since they would fit in a cache line.
Project Valhalla Link to heading
Project Valhalla is one of the major evolutionary projects on the JVM, and has been going on for a while - since 2014, and unfortunately is not yet close to be ready! It has gone through multiple iterations, but the core idea is to allow programmers to create new value classes with different semantic from the standard Java classes, and to rely on the different guarantees to improve performances. Furthermore, another aim is to improve the support of generic code for primitive types, to avoid paying the overhead of the wrapper classes.
The slogan for project Valhalla is:
Codes like a class, works like an int.
The main evolution will be the ability to declare a value class, which will have various differences from a standard class:
- it will have no identity so:
- you will not be able to use it for
synchronized - every instance will be freely copyable
- it will be comparable with
==
- you will not be able to use it for
- and it will be immutable (like
records).
These rules will allow for a lot of new runtime optimization - which might include allocating these objects on the stack or even in registers, rather than the heap. This is something that the JVM actually already does under some circumstances to be fair, but by declaring a value class these optimizations will always be enabled.
Furthermore, declaring value classes will allow you to express your intent more clearly, and in my opinion design clarity is a very good thing.
However, you will still have a reference to a value class - meaning, your variable of type X might be null or not. Therefore, project Valhalla is going further and it is planning to add also primitive class to the language, which will be a sort of “super-value class”, that behaves like a primitive. The main difference is that a reference to a primitive class cannot be null - just like an int variable cannot. This allows a further set of optimizations in the JVM, in addition to those for any value class.
For example:
primitive class Point implements Serializable {
int x;
int y;
Point(int x, int y) {
this.x = x;
this.y = y;
}
Point scale(int s) {
return new Point(s*x, s*y);
}
}
Point p = new Point(1, 2);
assert p.scale(2) == new Point(2, 4);
Notice how you will be able to write constructors, methods, or implement interfaces for value and primitive classes.
There’s a lot more work planned under the project’s umbrella, including the evolution of generics to make things like List<int> possible and faster, with a runtime memory layout closer to what you would do in a lower-level language like C++ or Rust. Unfortunately, these future enhancements are further down the road, and will take a few more years to reach production.
However, what is already planned and being developed will have significant performances benefits, especially since it is planned that the JDK classes will be migrated to value classes wherever it makes sense - so your code will go faster, without the need for changes (well, unless you are synchronizing over a LocalDate rather than a proper Lock, of course…).
No release date is planned yet, unfortunately, but work is progressing, and hopefully we will have a preview version in a not-so-distant Java version!
Further reading Link to heading
Baeldung has a good introduction.
But, if you want the details, by far the best and the most up-to-date reference is a series of three articles by Brian Goetz - who not only leads the development of Java, but is also the author of one of my favorite programming book.
- The first article talks about background motivation and what project Valhalla aims to solve;
- the second article goes into detail of the Java language changes;
- and the last part focuses more on the JVM details, including the new bytecode operations.
Finally, there is a draft JEP for the universal generics.
Post scriptum - Primitive boxing optimizations Link to heading
As an aside, something I have always found interesting is the cool tricks used by the JDK in the primitive wrapper implementation. For example, the method Integer::valueOf has this implementation in the JDK I’m currently using:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
The private IntegerCache class caches all values between -127 and 128 by default. Thus, whenever you create an Integer via the valueOf factory method and a value of (say) 1, you will always get the same instance! That is, incidentally, why your IDE or static analysis tool complains if you use new Integer(n) rather than Integer.valueOf(n) - you are creating a new object that will need to be garbage-collected, and are missing the opportunity of reusing an instance that will always be alive.